

В качестве новаторской разработки Meta представила ImageBind, инновационную модель искусственного интеллекта, которая устраняет разрыв между машинами и людьми с точки зрения целостного обучения из нескольких модальностей. В отличие от традиционных систем искусственного интеллекта, которые полагаются на определенные встраивания для каждой модальности, ImageBind создает общее пространство представления, позволяя машинам одновременно учиться на основе текста, изображения/видео, звука, глубины, тепловых и инерциальных единиц измерения (IMU). В этой статье исследуется огромный потенциал ImageBind и его влияние на будущее искусственного интеллекта.
ImageBind включает в себя несколько сенсорных входов для создания медиа
ImageBind представляет собой значительный шаг вперед в возможностях ИИ, преодолевая ограничения предыдущих специализированных моделей, обученных отдельным модальностям. Включая несколько сенсорных входов, ImageBind предлагает машинам всестороннее понимание, которое объединяет различные аспекты информации. Например, Make-A-Scene от Meta может использовать ImageBind для создания изображений на основе аудио, что позволяет создавать захватывающие впечатления, такие как тропические леса или шумные рынки. Кроме того, ImageBind открывает двери для более точного распознавания контента, модерации и креативного дизайна, включая бесшовное создание мультимедиа и расширенные функции мультимодального поиска.
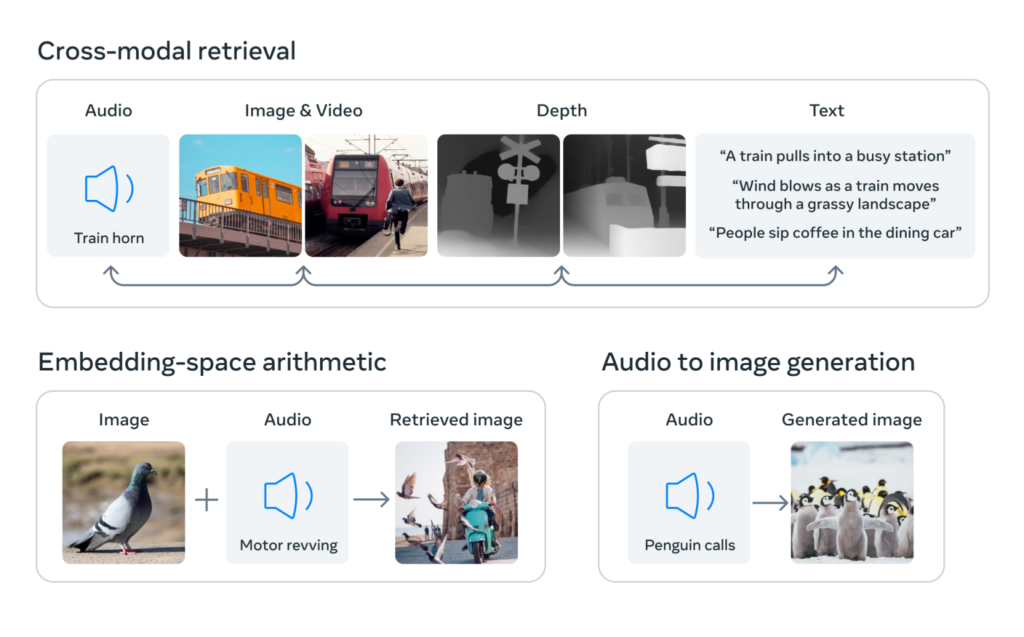
В рамках более широких усилий Meta по разработке мультимодальных систем искусственного интеллекта ImageBind закладывает основу для исследования новых границ исследователями. Способность модели сочетать 3D-датчики и датчики IMU может произвести революцию в дизайне и восприятии иммерсивных виртуальных миров. Кроме того, ImageBind предлагает широкие возможности для изучения воспоминаний, обеспечивая поиск по различным модальностям, таким как текст, аудио, изображения и видео.
Создание совместного пространства для встраивания нескольких модальностей уже давно представляет собой проблему в исследованиях ИИ. ImageBind обходит эту проблему, используя крупномасштабные модели языка видения и используя естественные пары с изображениями. Выравнивая модальности, которые встречаются вместе с изображениями, ImageBind легко соединяет различные формы данных. Модель демонстрирует возможность целостной интерпретации контента, позволяя различным модальностям взаимодействовать и устанавливать значимые связи без предварительного совместного обучения.
Уникальное поведение масштабирования ImageBind показывает, что его производительность улучшается с увеличением моделей машинного зрения. Благодаря самоконтролируемому обучению и использованию минимальных обучающих примеров модель демонстрирует новые возможности, такие как связывание аудио и текста или прогнозирование глубины изображения. Более того, ImageBind превосходит предыдущие методы в задачах аудио и классификации глубины, достигая значительного прироста точности и даже превосходя специализированные модели, обученные исключительно этим модальностям.
С помощью ImageBind Meta прокладывает путь для машин, чтобы учиться на различных модальностях, продвигая ИИ в новую эру целостного понимания и мультимодального анализа. Компания добилась значительных успехов в области ИИ, и некоторое время назад компания запустила собственную модель ИИ.